SPIRAL®の「30秒の壁」を突破せよ!
外部サーバ連携による大量データ処理の最適化

- SPIRAL
「クラウドサービスは便利だけど、自由度が低くてかゆいところに手が届かない......」
そんな経験はありませんか? 今回は、SPIRAL®のPHP実行時間制限(30秒)をストリーミング処理で
回避した実装事例をご紹介します。
回避した実装事例をご紹介します。
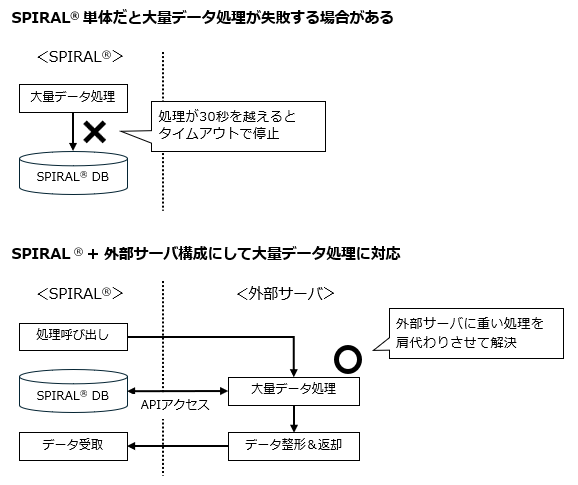
■【課題】大量CSV処理で直面する「30秒の壁」
今回の自治体向けWeb申請システムでは、堅牢なPaaS基盤であるSPIRAL®を採用しました。しかし、大量データを扱う処理では、標準機能の範囲だけで完結させることが難しい場面がありました。
自治体案件では、扱うデータが数十万件規模におよぶケースがあります。
- ・大量の申請データをCSV形式で一括ダウンロードしたい
-
・CSVを読み込ませてデータベースを一括更新したい
こうした要件に対し、SPIRAL®のPHP実行環境にはいわば「30秒の壁」という実行時間制限があります。大量レコードを一度に処理しようとすると、処理の途中でタイムアウトが発生し、処理が正常に完了しないリスクがありました。
■【解決】外部サーバへのオフロードとストリーミング出力
この制限を回避するため、実行環境のカスタマイズが容易な外部サーバを処理実行エンジンとして活用しました。
JavaScript側では複雑な制御を行わず、単一のリクエストで処理を開始し、負荷の高い処理は外部サーバ側に委ねる設計にしています。
JavaScript側では複雑な制御を行わず、単一のリクエストで処理を開始し、負荷の高い処理は外部サーバ側に委ねる設計にしています。
■技術的アプローチ:メモリを圧迫しないデータ処理
単に外部へ処理を委ねるだけでは、外部サーバ側でもメモリ不足やタイムアウトが発生する可能性があります。そこで以下の工夫を加えました。
フロントエンド処理のシンプル化:
フロントエンド(JS)側での複雑なループ制御を廃止し、サーバ側でスパイラルAPI(SPIRAL®で提供されるAPI)との通信から加工までを一貫して処理することで、通信のオーバーヘッドを最小限に抑えています。
ZipStream-PHPの活用:
ダウンロード処理では、全データをメモリに展開してから圧縮するのではなく、「生成しながら順次ブラウザへ送信する(ストリーミング)」方式を採用しました。
これにより、大容量のZipファイルもサーバのメモリを圧迫せずに安定して生成できます。
結果として、SPIRAL®の堅牢さを活かしつつ、数十万件のデータを淀みなく処理できるパワフルなバックエンドを実現しました。
■まとめ
-
・SPIRAL®の30秒制限により、大量CSV処理ではタイムアウトが課題になります
-
・外部サーバへ処理をオフロードすることで、負荷の高い処理を安定化できます
-
・ZipStream-PHPのストリーミング出力により、メモリ消費を抑えられます
次回は「境界線の守り方 ―― JWT認証とセッション管理で実現する防衛術」をお届けします。